Crawler là gì là vấn đề khá lạ lẫm với người dùng website và những người mới làm marketing. Crawler giữ vai trò quan trọng trong quá trình duyệt website, tuy nhiên không phải ai cũng hiểu rõ cách thức hoạt động cũng như cách xây dựng crawler hiệu quả. Trong bài viết này mình sẽ chia sẻ những thông tin về khái niệm crawler và những yếu tố ảnh hưởng tới crawler, anh em có thể tham khảo ngay nhé.
Crawler là gì?
Những người làm trong lĩnh vực marketing hay cụ thể hơn là SEO website thường sử dụng các khái niệm như Crawler, Crawl Data hoặc Crawl dữ liệu. Vậy khái niệm Crawler là gì? Trên thực tế khái niệm Crawler là thuật ngữ rất quen thuộc với dân SEO, dùng để gọi tên kỹ thuật mà robots của các công cụ tìm kiếm (như Google, Bing hay Yahoo,…) sử dụng.

Crawler đóng vai trò là công cụ thu thập dữ liệu, thông tin từ các trang web khác, thực hiện phân tích mã nguồn để đọc dữ liệu. Quá trình này sẽ tuân theo nhu cầu của người dùng hoặc theo Search
Mô hình web Crawler là gì?
Web Crawler hay trình thu thập thông tin web, là công cụ có chức năng tải xuống và index với content trên toàn bộ mạng Internet. Kỹ thuật Crawler được ứng dụng để truy cập tự động và lấy dữ liệu thông qua phần mềm. Mục đích khi sử dụng mô hình Web Crawler là thu thập thông tin để biết website đang nói về điều gì và truy xuất thông tin cần thiết. Hiện tại các bot này sẽ được điều hành bằng các công cụ tìm kiếm.
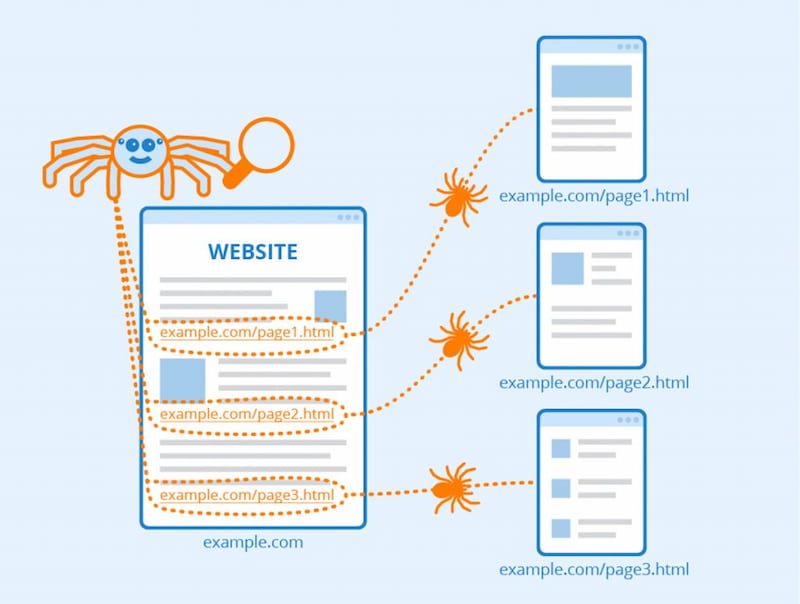
Ứng dụng tuyệt vời nhất của Crawler là gì? Crawler thực hiện vai trò thu thập dữ liệu và tạo danh sách các liên kết có quan hệ mật thiết để phục vụ các nhu cầu của người dùng. Khi đã thu thập được dữ liệu, công cụ này sẽ có nhiệm vụ phân tích và đưa ra các trang web cần hiển thị khi có các truy vấn từ người dùng.
Những tên gọi khác của Crawler là gì?
Như đã giới thiệu ở trên, Crawler có rất nhiều tên gọi khác nhau, do đó, tùy vào hoàn cảnh hay tùy từng người sẽ có cách gọi riêng, anh em chỉ cần biết để nhận diện là được. Bất kể tên gọi khác của Crawler là gì thì ý nghĩa và nhiệm vụ vẫn sẽ không thay đổi, anh em có thể xem qua các tên gọi khác dưới đây nhé:
- Spider: Mang ý nghĩa là một con nhện, đây là hình tượng hóa mà nhiều người dành cho Crawler để nói về sự lan toả, len lỏi vào từng ngõ ngách trang web để truy cập vào từng liên kết.
- Ant: Cũng giống như Spider, Ant cũng là hình tượng mô phỏng khi con kiến di chuyển và tiết ra một chất có tên pheromone để tạo dấu vết. Điều này cũng giống như crawler đánh dấu liên kết khi di chuyển qua các website.
- Crawler: Đây là tên gọi phổ biến nhất, thể hiện đúng chức năng của kỹ thuật này. Crawler mô tả lại hành động truy cập dữ liệu crawl trên một website, giống với hành động bò hay trườn trên trang web.
- Bot: Việc sử dụng tên gọi Bot cho các crawl thực chất cũng chưa chính xác lắm, tuy nhiên nó vẫn được rất nhiều người lựa chọn. Thực tế, web crawler chỉ là tập hợp con của Internet Bot.
Cách thức hoạt động của Crawler là gì?
Việc đo đếm các trang web hiện nay là vô cùng khó bởi thế giới internet hiện nay phát triển với tốc độ chóng mặt. Đây là lúc các crawler phát huy tác dụng của mình. Vậy cách thức hoạt động của crawler là gì?
Trước hết, Crawler sử dụng danh sách các URL có sẵn và tiến hành thu thập những dữ liệu tại các URl này. Sau khi quét qua các URL sẵn có, crawler sẽ phát hiện những siêu liên kết URL khác và tự bổ sung vào danh sách URL sẵn có.

Việc thu thập dữ liệu, quét thông tin có thể diễn ra vô tận khi số lượng các trang web vô cùng khủng, chính vì vậy các web crawler sẽ cần tuân thủ những chính sách cố định. Điều này sẽ giúp trình thu thập thông tin trở nên hiệu quả, từ đó có thể thu thập được những thông tin liên quan, ưu tiên những liên kết mới.
Ngoài ra, khi sử dụng crawler cũng sẽ xác định được những trang web cần thu thập thông tin, tần suất thu thập,… Quá trình thu thập của Crawler sẽ tự động và không phụ thuộc vào yếu tố con người. Sau khi thu thập đủ dữ liệu, crawler sẽ tổng hợp với dữ liệu ngoài trang, số lượng backlink trỏ đến ngoài trang, lượng truy cập,… và gửi tới ngân hàng dữ liệu.
Những yếu tố ảnh hưởng đến Crawler
Crawler có vai trò rất quan trọng đối với quá trình index lên Google, vậy những yếu tố có thể ảnh hưởng đến Crawler là gì? Cụ thể một số yếu tố mà mình muốn đề cập như sau:
- Domain: Để website crawler được đánh giá cao và xuất hiện với thứ hạng cao trên Google thì bắt buộc tên miền phải chứa từ khóa chính được đánh giá tốt. Hiện tại công cụ có khả năng đánh giá chất lượng domain là Google Panda, chính vì vậy anh em có thể kiểm soát chất lượng domain dễ dàng hơn.
- Backlink: Xây dựng backlink chất lượng cũng sẽ giúp website thân thiện với các công cụ tìm kiếm hơn, do đó anh em nên chú ý làm backlink cho website.
- Internal Link: Là các liên kết nội bộ trong một website, là yếu tố vô cùng quan trọng khi tiến hành làm SEO. Khi thêm Internal Link phù hợp sẽ giúp người dùng ở lại trang web lâu hơn, tăng thời gian onsite lâu hơn.

- XML sitemap: Là yếu tố giúp Google index nhanh hơn.
- Duplicate Content: Khi bị trùng lặp nội dung trên website, hãy khắc phục bằng cách chuyển hướng 301 hoặc 404 để đạt hiệu quả crawling, đảm bảo quá trình SEO cho WordPress hiệu quả hơn.
- URL Canonical: Đường dẫn thân thiện cho website cũng là yếu tố giúp hỗ trợ cho website, đảm bảo website thân thiện hơn với công cụ tìm kiếm.
- Meta Tags: Khi chèn meta tags phù hợp, độc đáo cũng sẽ đảm bảo website đạt thứ hạng cao trên thanh tìm kiếm.
Những câu hỏi liên quan
Web Crawler có nên truy cập thuộc tính web không?
Sau khi nghiên cứu về crawler là gì, rất nhiều người có thắc mắc không biết có nên cho bots crawler truy cập vào thuộc tính web hay không? Mục đích của crawler là lấy dữ liệu làm cơ sở để index nội dung. Do đó, tùy thuộc vào số lượng trang web hoặc số lượng nội dung mà những người quản lý, vận hành trang web sẽ quyết định có nên index các tìm kiếm thường xuyên không. Trong trường hợp index quá nhiều, nguy cơ lỗi máy chủ hoặc tăng chi phí băng thông sẽ dễ xảy ra, do đó việc web crawler truy cập thuộc tính sẽ bị hạn chế hơn.
Sự khác biệt giữa Web Scraping và Web Crawler là gì?
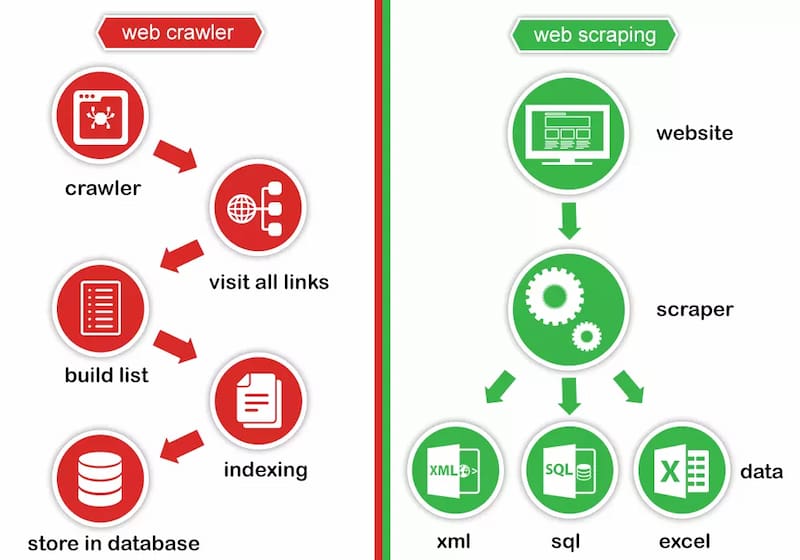
Web Scraping hay còn gọi là data scraping, content scraping, là việc một con bot tải xuống nội dung trên một trang web nhưng không được sự cho phép của chủ website. Thông thường những hành động tải xuống này thường có mục đích xấu.
Web scraping thường chỉ có thể theo dõi một số trang web cụ thể, trong khi đó web crawler có thể thu thập thông tin từ nhiều trang web khác nhau và thực hiện liên tục. Ngoài ra, web scraper có thể qua mặt máy chủ tương đối dễ dàng, ngược lại web crawler không như vậy.
Các crawler ảnh hưởng thế nào đến SEO?
Tối ưu trang web chuẩn SEO là cách để Google có thể index lên danh sách kết quả tìm kiếm. Điều đó đồng nghĩa với việc, nếu các bot crawler không thu thập dữ liệu thfi trang web sẽ không thể hiển thị được trên kết quả tìm kiếm.
Các Web Crawler phổ biến nhất hiện nay

Hiện nay có các Web Crawler phổ biến và tồn tại dưới các dạng như:
- Google: Có 2 trình thu thập dữ liệu là Googlebot Desktop và Googlebot Smartphone.
- Bing: Thực hiện chức năng tương tự như Googlebot của Google, có tác dụng thu thập tài liệu để xây dựng chỉ mục tìm kiếm cho Bing.
- Yandex: Là trình thu thập dữ liệu của Yandex.
- Baidu: Có khả năng thu thập dữ liệu website và trả về bản cập nhật chỉ mục Baidu.
Lời kết
Trên đây là những chia sẻ về khái niệm crawler là gì, hi vọng với những thông tin này sẽ giúp anh em hiểu được tầm quan trọng của crawler và đầu tư chỉnh sửa ngay cho website của mình. Đừng quên theo dõi thêm những thông tin, kiến thức marketing mới tại Vsign nhé.






")